





로봇 팔 시스템 지능제어와 응용
정슬 충남대 메카트로닉스공학과 교수 (jungs@cnu.ac.kr)
로봇 시스템 제어와 응용이란 주제로 6회에 걸쳐 연재하게 되었다. 로봇이란 분야는 너무 방대하고 내용이 많아 6회에 모두 소화하지는 못하지만, 지난 수십 년간 연구한 결과를 바탕으로 독자와 만나는 방식으로 전개하고자 한다. 이번 호에서는 로봇의 가장 기초인 로봇 팔의 지능제어와 응용을 소개하고자 한다.
로봇 팔 시스템
로봇 팔은 다소 진부하며 흥미롭지 않게 들릴 수 있다. 하지만 로봇 팔은 인간의 팔이 할 수 있는 일을 대신 하도록 만들어졌기 때문에 모든 로봇의 기초가 되며, 실제 산업에서 가장 많이 사용되고 있는 것이 현실이다. 그림 1은 충남대 ISEE실험실에서 만든 로봇이다.
최근에 로봇의 관심이 휴머노이드 로봇이나 서비스 로봇으로 이동하고 있지만, 결국 중요한 기술은 매니퓰레이션 기술이다. 궁극적으로는 휴머노이드 로봇이나 서비스 로봇도 로봇 팔을 사용하여 작업해야 하기 때문이다.
로봇 팔 시스템의 제어
1. 로봇 팔의 동역학
로봇 팔의 가장 중요한 역할은 정확한 움직임이다. 하지만 로봇 팔은 동적 시스템이므로 정확한 움직임을 방해하는 요소들이 존재한다. 예컨대, 로봇 팔에 달린 물체의 하중, 기어의 백래시, 각 관절의 마찰력 등이 그러한 요소들이다. 동역학식을 표현하면 다음과 같다.
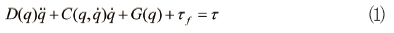
여기서 q는 조인트 벡터, D(q)는 관성행렬, C(q, q)q)는 코리올리스와 원심력 벡터, G(q)는 중력벡터, τf는 불확실성 벡터, 그리고 τ는 입력 토크벡터이다 식 (1)에서 볼 수 있는 것처럼 로봇 팔은 다중입출력 시스템이고 비선형이며 각 조인트가 결합된 시스템이다. 따라서 각 조인트의 움직임은 다른 조인트에 영향을 주게 된다.
제어란 이러한 방해 요소, 즉 불확실성을 효과적으로 처리하는 기술이다.
2. 무모델 기반 PID 제어 방식
가장 간단하며 많이 사용되는 PID 제어기를 사용하는 경우를 살펴보자. PID 제어 법칙은 다음과 같다.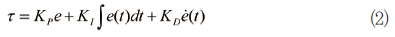
여기서 e=qd-q이다. 식 (1)과 (2)를 등식으로 놓으면 다음과 같다.
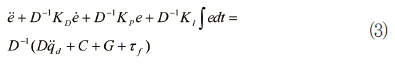
정착상태에서는

여기서 PID 이득값을 크게 하면 오차는 줄일 수 있겠지만, 하드웨어의 한계로 제한된다. 또한, 불확실성은 비선형이고 결합되어 있으므로 정확한 상쇄가 어렵다. 이를 해결하기 위해 모델 기반 제어방식을 살펴보자.
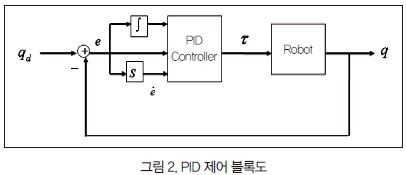
3. 모델 기반 계산 토크제어 방식
그림 3에 나타난 모델을 사용하는 계산 토크 방식의 제어법칙은 다음과 같다.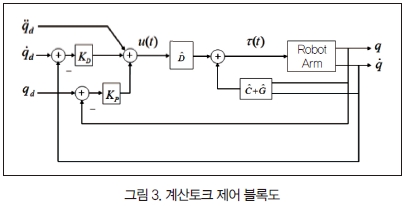
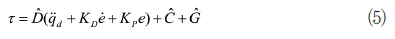
여기서 D, C, G는 각각 D, C, G의 모델이다
식 (1)과 식 (5)를 등식으로 놓으면
여기서 Λ=D-1()이고 ΔD=D-D, ΔC=C-C, ΔG=G-G으로 모델링 오차가 된다. 만약 모델링 오차와 불확실성이 없으면 식 (7)과 같다.
제어기 이득을 대각 요소로 선택하게 되면 각 조인트를 분리하여 제어할 수 있게 된다. 따라서 비선형이며 결합된 동역학의 문제를 해결할 수 있다.
하지만 서두에서 말한 것처럼 불확실성은 모델이 되지 않고 모델은 항상 오차를 수반하고 있기 때문에 식 (7)을 만족하는 것은 불가능하다.
4. 지능제어 방식
그렇다면 식 (7)을 만족하기 위해서는 어떻게 할까? 궁극적으로 모델링 오차를 포함하는 불확실성을 없애기 위해서는 식 (6)에서 추가적인 보상신호를 통해 제거한다.

여기서 Φ는 보상신호이다. 어떻게 이 보상신호를 만들어 내는가에 따라 다양한 제어방식이 제안되었다.
이 글에서는 많은 제어방식 중에서 지능제어 방식을 소개하고자 한다. 다른 방식에 대한 자세한 내용은 [1-3]을 참고하기 바란다. 지능제어 방식 중에서 신경회로망과 퍼지를 혼합하는 제어방식을 소개하고자 한다. 또한, 기존의 뉴로-퍼지 제어방식과는 다른 개념의 혼합방식을 기술한다.
퍼지제어기의 외부에 신경망 제어기를 첨가하는 방식은 보상하는 위치에 따라 두 가지가 있다. 입력에 보상하는 입력 보상 방식(Reference compensation technique : RCT)과 토크에 보상하는 방식(Feedback error learning: FEL)의 형태를 보이는 신경회로망 보상 퍼지 제어기를 소개한다. 제안하는 제어방식의 성능을 검증하기 위해 그림 1의 로봇의 왼쪽 팔을 사용하여 실험했다. PID 제어기와 퍼지 제어기 그리고 제안하는 신경망회로망 보상 퍼지 제어기로 실험하여 각 제어기의 성능을 비교해 보았다.
퍼지 제어기
퍼지 제어에서는 제어 변수와 이에 따른 소속 함수의 설정, 제어 규칙의 정의, 그리고 제어 변수의 정규화 과정 등이 필요하다. 그림 4에 보면 퍼지 제어기의 구조가 나타나 있다. 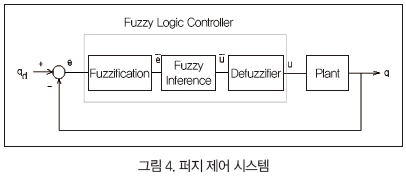
퍼지 제어기는 입력 변수가 오차와 오차의 미분형태로 2개이고, 규칙 기반이 49개인 일반적인 PD 형태의 퍼지 제어기가 기본이다. 일반적으로 퍼지 법칙을 작성하기 위해서는 그 시스템에 대한 전문적인 지식이나 작동 특성 등을 잘 알고 있어야 한다. 그렇지 않으면 퍼지 법칙을 작성하는 데 많은 어려움이 작용하게 된다.
각 제어 변수들의 소속 함수는 그림 5와 같으며, 각 소속 함수는 모두 [-1, 1]에서 정규화시킨 값을 사용한다.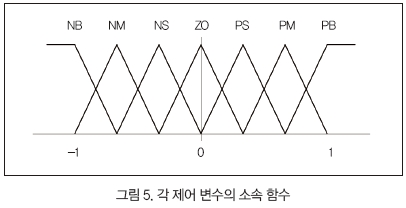
위 소속 함수를 기반으로 Mamdani의 제어 규칙을 설정하면 다음과 같이 나타낼 수 있다.
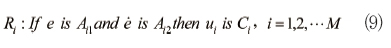
여기서 Aij, Ci는 언어적인 표현이다. 따라서 이를 룰로 작성한다.
무게 중심법에 의한 출력 값은 다음과 같다.
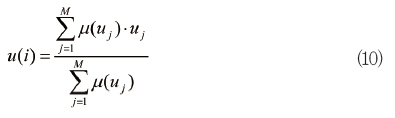
여기서 μ(uj)는 소속함수, uj는 퍼지집합 u 한 값이다.
일반적으로 퍼지 시스템은 식 (11)과 같이 표현된다.

식 (11)은 기본 퍼지 함수의 선형 조합에 의해 아래와 같이 표현된다.

여기서 퍼지 기본 함수는 다음과 같다.

여기서 X=(x1, x2, Λ,… xn).
퍼지 시스템의 비선형 함수 근사화 능력은 다음과 같이 다항식 로 어느 정도의 오차 범위 안에서 수렴한다.

여기서 εf는 함수의 근사오차이다.
PD 형태의 일반 퍼지 제어기만을 사용하게 되면 퍼지 제어기가 비선형이므로 비선형 시스템을 제어하는 데 있어서 선형 제어기를 사용하는 것보다는 성능이 우수하다. 하지만 외란이나 불확실성에 능동적으로 대처하는 능력은 저하된다. 이를 보완하기 위해 뉴로 퍼지 제어기를 사용한다.
신경회로망 보상 퍼지 제어기
퍼지 제어기는 시스템이 변화하게 되면 이에 맞춰 정규화 값을 변경해 주거나 제어기의 규칙을 수정해야 하는 번거로움을 안고 있다. 이러한 단점들을 해결하기 위해 신경회로망을 이용한 퍼지 규칙의 자동 생성 기법은 다층 신경회로망의 각 층을 퍼지화, 추론, 비퍼지화 등과 같은 각 퍼지 제어 방식의 진행 과정을 나타냄으로써 자동적으로 퍼지 법칙을 조절하는 역할을 한다. 이는 신경회로망과 퍼지 제어의 장점만을 사용하여 시스템의 성능을 좋게 하는 결과를 보여 준다.
이 글에서는 퍼지 제어기와 신경회로망 제어기를 함께 사용하는 제어방식을 소개한다[4]. 기존의 퍼지 제어기를 사용하고 외부에서 신경회로망 제어기로 보상하는 방식이다. 신경회로망에 보상하는 위치 구조에 따라 두 가지 방식이 있다.
1. FEL 신경회로망 보상 퍼지 제어
기존의 퍼지 제어기를 그대로 사용하고 신경회로망 제어기를 보조제어기로 첨가하여 오차를 줄이는 방식이다. Feedback error learning(FEL) 방식의 경우 제어 입력(토크)에 신경회로망의 출력 신호를 더하여 보상한다(그림 6).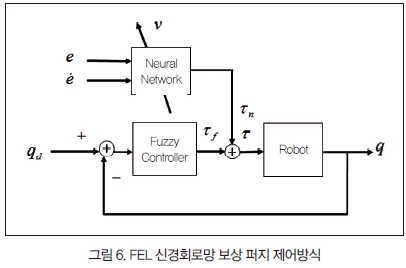
신경회로망의 출력이 PD 형태의 퍼지 제어기의 출력에 더해진다. 결과적으로 출력 τ는 두 출력이 더해져서 다음과 같다.

여기서 학습신호는 다음과 같이 정한다.

신경망의 목적 함수는 
목적함수를 가중치로 미분하면 다음과 같다.

이 값을 역전파 알고리즘에 적용한다.
2. RCT 신경회로망 보상 퍼지 제어
그림 7은 RCT 기반의 신경회로망-퍼지 제어기의 블록선도를 나타낸다. 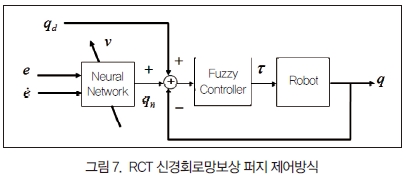
제안하는 방식은 기준 경로 입력에 보상한다. 따라서 FEL 기반의 방식과 비교해서 RCT 기반의 방식은 시스템의 내부를 건드리지 않고 외부에서 보상하는 구조적인 장점이 있다.
그림 7에서 오차 신호는 다음과 같이 구성된다.

PD 형태의 퍼지 제어기의 출력 τ는 1차 다항식으로 근사화할 경우에 다음과 같다.
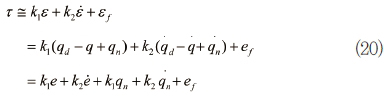
여기서 k1, k2는 퍼지 법칙에 의해 결정되는 퍼지 상숫값이고, e=qd-q이다. 여기서 정리하면, 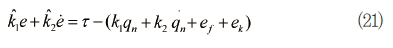
여기서 k1, k2는 k1, k2의 근사치이고 ek는 이득값의 근사화 오차이다. 신경망의 학습신호를 다음과 같이 정의 한다.

신경망의 목적함수는

목적함수를 가중치로 미분하면 다음과 같다.
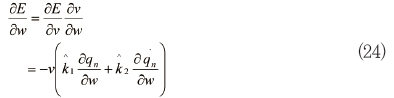
이 값을 역전파 알고리즘에 적용한다.
제어기의 성능 평가
1. 실험 환경
그림 8은 로봇 팔의 제어 실험 환경을 나타낸다. 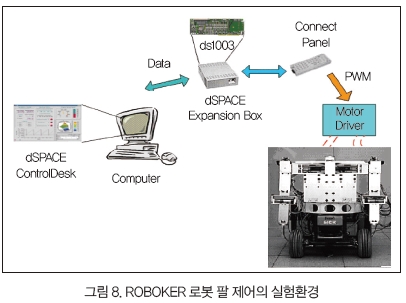
직교 좌표 공간의 기준 경로는 역기구학을 통하여 컴퓨터에서 연산되어 로봇의 각 조인트의 기준 입력으로 주어진다. 이 기준 경로를 로봇이 잘 추종하도록 PID 제어기, 퍼지 제어기, 신경망 보상 퍼지 제어기를 사용했다. DSP로 신경회로망 연산을 실시간으로 수행하여 매 샘플링 시간마다 각 조인트에 명령어를 보내어 움직임을 제어했다.
2. PID 제어 결과
첫 번째 실험에서는 PID 제어기를 사용했으며, 그 결과는 그림 9와 같다.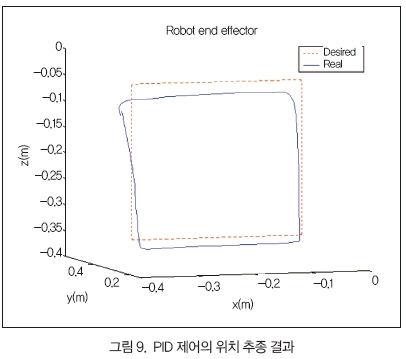
PID 제어기의 이득값은 실험적으로 시행착오를 거쳐 선택했다. 오차는 매우 크게 나타나고 있는 것을 확인 할 수 있다.
3. 퍼지 제어 결과
다음 실험은 퍼지 제어기만을 사용한 것으로 실험 결과는 그림 10과 같다. 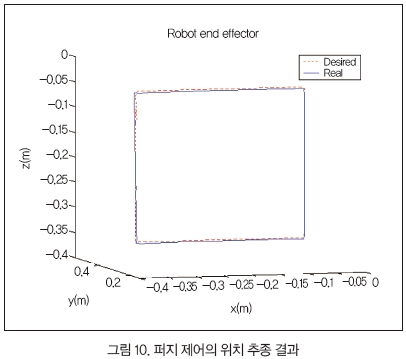
오차를 보면 PID 제어기의 경우보다 줄어듦을 알 수 있다.
4. FEL 신경망 보상 퍼지 제어 결과
다음 실험으로 FEL 신경망 보상 퍼지 제어방식을 이용한 실험으로 결과는 그림 11에서 보는 바와 같다. 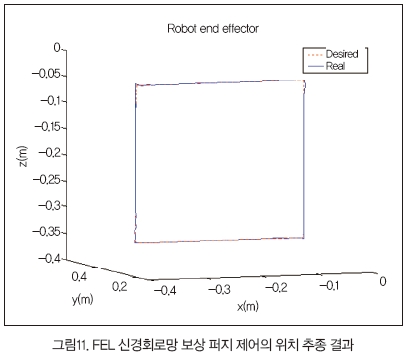
오차를 보면 퍼지 제어기보다 더 작은 오차를 나타냄을 알 수 있다.
5. RCT 신경망 보상 퍼지 제어 결과
마지막으로 입력에 보상하는 RCT 신경회로망 보상 퍼지 제어 방식을 실험했다. 실험 결과는 그림 12에 나타나 있다.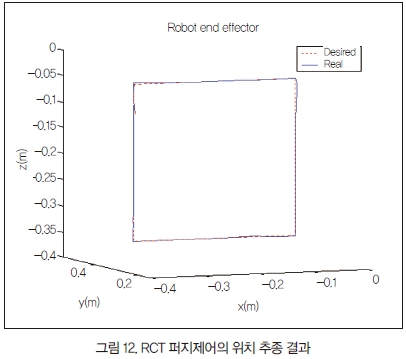
그 실험 결과를 살펴보면 FEL 신경회로망 보상 퍼지 제어방식과 RCT 신경회로망 보상 퍼지 제어방식의 결과가 유사하게 나타났다. 








































