
[첨단 헬로티]

IT기기를 사랑하는 사용자들은 물론이고 일반적인 소비자들도 분명 5년 전과 비교하여 현재 훨씬 더 많은 디바이스를 소유하고 있을 것이다. 또한 스마트폰에서부터 태블릿, 개인용 건강추적기(fitness tracker), 스마트 천식 흡입기, 스마트 도어벨에 이르기까지, 해마다 모든 기기들이 서로 빠른 속도로 연결되고 있으며, 이로 인하여 개인 데이터의 사용량도 폭발적으로 성장하고 있다.
독일의 시장조사기관인 스태티스타(Statista)의 최근 보고서에 따르면, 전세계 1인당 커넥티드 디바이스 보유 수는 지난 10년간 큰 증가폭을 보이며 평균 2대 미만에서 2020년에는 6.58대에 이를 전망이다. 엄청난 수의 디바이스가 엄청난 양의 데이터를 생산하고 있는 것이다.

최근까지 이렇게 생산된 데이터는 프로세싱을 위해 자연스럽게 클라우드로 보내졌다. 하지만 데이터의 양과 디바이스의 수가 기하급수적으로 증가하면서, 이 모든 데이터를 계속 송수신하는 것은 안전하지도, 비용 효율적이지도 않을 뿐만 아니라 실용적이지 않다.
다행히 최근 머신러닝의 발달로 이제 어느 때보다 더 많은 온디바이스 프로세싱 및 프리프로세싱을 수행할 수 있게 됐다. 온디바이스 프로세싱은 데이터 노출 위험을 줄여, 안전과 보안에서부터 비용 및 전력 절감에 이르기까지 다양한 이점을 제공한다. 데이터를 클라우드에 송수신하는 인프라는 높은 비용을 야기하므로 보다 많은 양의 프로세싱을 온디바이스로 진행하는 것이 훨씬 효율적며 안전하다.
고성능을 자랑하는 전력과 효율성
온디바이스 머신러닝 처리는 CPU를 이용한 단일 처리 방식으로 전체 머신러닝 워크로드를 관리하거나, 또는 특정 머신러닝 프로세서에 관련 작업을 선택적으로 분배하여 처리할 수도 있는 능숙한 '트래픽 컨트롤러’의 역할을 한다. Arm CPU와 GPU는 이미 여러 응용 분야 전반에 걸친 수천 개의 머신러닝 활용 사례에서 적용되고 있다. 특히 모바일 사용 사례가 두드러지는데, 엣지 머신러닝이 제공하는 기능들은 이제 소비자들이 기본적으로 기대하는 수준을 갖추고 있다. 특히 보다 강력해지고 효율성이 높아진 관련 프로세서들은 기존보다 더 높은 성능을 제공해, 엣지에서도 안전한 머신러닝을 위한 온디바이스 컴퓨팅 능력을 갖출 수 있도록 한다.
그러나 CPU와 GPU가 자체적으로 머신러닝을 구동하는 데에는 매우 강력하고 효율적인 성능이 요구되며, 관련 요구사항을 충족하는 데에는 많은 어려움이 존재한다.
Arm 전용 NPU의 강력한 기능은 엣지에서 머신러닝 추론을 위해 높은 수준의 처리량과 효율적인 프로세싱을 제공하는 등 그 진가를 발휘한다.
NPU를 통한 새롭고 흥미로운 경험 실현
그렇다면 Arm 머신러닝 프로세서의 특별한 점은 무엇일까? Arm 머신러닝 프로세서는 새로운 아키텍처에 기반해 스마트폰, 스마트 카메라, AR 및 VR 디바이스, 드론 등의 커넥티드 디바이스와 의료용 및 소비자용 가전 제품에서까지 이용된다.
수치로 이야기하자면 최대 4 TOP/s의 뛰어난 성능을 자랑하며, 이를 통해 제한된 배터리 수명이나 발열 때문에 이전에는 불가능했던 새로운 사용 사례를 실현할 수 있다. 또한 개발자들은 3D 안면 인식 잠금 해제나 심도 조절, 인물 조명 등을 포함한 고급 인물사진 모드 등 새로운 사용자 경험을 제공할 수 있다.
성능이 훌륭한 것도 중요하지만, 사용자가 디바이스를 매시간 충전해야 하거나 보조 배터리를 들고 다녀야 한다면 사용이 매우 곤란할 것이다. 머신러닝 프로세서는 위노그라드(Winograd), 가중치(Weight) 및 액티베이션(Activation) 압축 등 첨단 최적화를 통해 5 TOPs/W에 달하는 업계 최고 전력 효율을 자랑하며, 이를 통해 사용자들이 거추장스러운 충전 케이블을 사용할 필요가 없도록 한다.
위노그라드는 더 작은 풋프린트로 핵심 컨볼루션 필터 성능을 다른 NPU 대비 225% 향상시켜, 효율적인 성능을 제공하면서 주어진 신경망(Neural Network) 회로 설계에 필요한 부품 수를 줄여준다. 이러한 향상은 사용자 경험을 저하시키지 않으면서 비용과 소비전력을 감소시켜 준다.
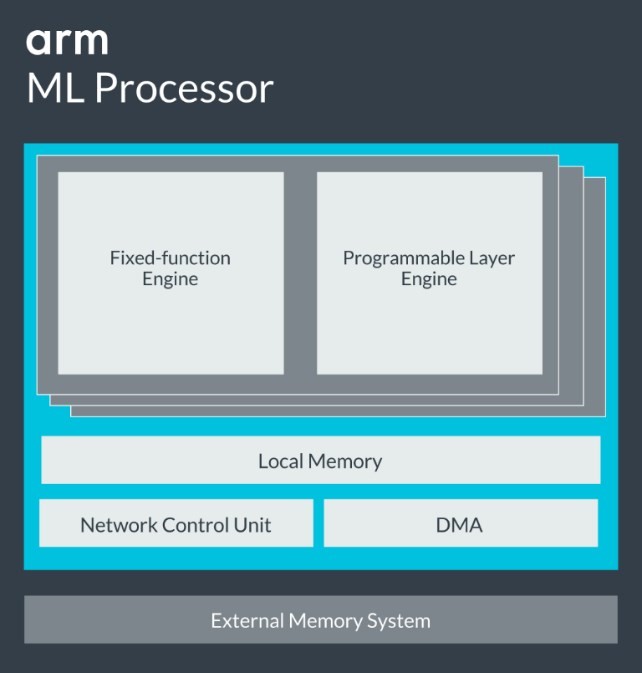
Arm NPU 아키텍처는 컨볼루션 레이어의 효율적인 실행을 위한 고정 함수 엔진(Fixed-function Engine)과 비(非)컨볼루션 레이어의 실행 및 선택된 프리미티브와 연산자 구현을 위한 프로그래머블 레이어 엔진(Programmable Layer Engine)으로 구성된다. 기본적으로 지원되는 이러한 기능들은 공통 신경 프레임워크와 밀접하게 연관되어 네트워크 배치에 소요되는 비용을 줄여 줄 뿐만아니라 제품 출시 기간까지 단축시킨다.
• 효율성: 최대 5 TOPs/W의 CPU, GPU, DSP, 엑셀러레이터로부터 비약적인 효율 향상을 제공한다.
• 네트워크 지원: 분류, 객체 검출, 이미지 향상, 음성 인식, 자연어 이해 등의 수행을 위해 컨볼루션(CNN), 순환 신경망(RNN)을 비롯한 다양한 인기있는 신경망을 처리한다.
• 보안: Arm 트러스트존(TrustZone) 아키텍처를 기반으로 사용하여 보안 노출에 대한 위험성을 최소화한다.
• 확장성: 멀티코어를 통해 단일 클러스터에서 최대 8 NPU 및 32 TOP 또는 메시 구성(Mesh-configuration)으로 64 NPU까지 확장할 수 있다.
• 신경 프레임워크 지원: ONNX를 통해 기존 프레임워크인 텐서플로(TensorFlow), 텐서플로 라이트(TensorFlow Lite), 카페(Caffe), 카페2(Caffe 2) 등을 통합 지원한다.
• 위노그라드 컨볼루션: 공통 필터를 다른 NPU 대비 225% 가속화하여 더 적은 공간에서 더 높은 성능을 제공한다.
• 메모리 압축: 다양한 압축 기술을 통해 시스템 메모리 대역폭을 최소화한다.
• 이기종 머신러닝 컴퓨팅: Arm Cortex-A CPU 및 Arm Mali GPU와 함께 사용하도록 최적화한다.
• 오픈 소스 소프트웨어 지원: Arm NN으로 지원되어 비용을 감축하고 록인(lock-in)을 방지한다.
유연한 설계로 미래 사용 가능성과 범용성 갖춰
Arm 머신러닝 프로세서는 개발자들이 쉽게 작업할 수 있도록 백그라운드에서 실행되는 메인 메모리의 데이터 입출력 뿐 아니라 네트워크의 전체적인 실행과 통과를 관리하는 통합 네트워크 제어 장치 및 DMA를 포함한다.
온보드 메모리는 가중치(Weight)와 특징 맵(Feature-map)을 중앙에 저장할 수 있게 해 외부 메모리로 이동하는 트래픽을 줄여줌과 동시에 배터리 수명을 늘려준다. 이는 소비자가 기대하는 또 하나의 머신러닝 시스템을 위한 중요한 요소가 된다.
결정적으로, Arm 머신러닝 프로세서는 더 높은 요구사항을 갖는 응용 분야를 비롯하여 다양하고 더 많은 수의 연산기능들을 지원하기에 충분히 유연하다. 즉, 단일 클러스터에서 최대 8개 코어를 구성하여 32 TOP/s 성능을 달성하거나 메시 구성으로 최대 64 NPU를 달성할 수 있다. 궁극적으로 Arm 머신러닝 프로세서는 성능과 효율성을 늘림과 동시에 네트워크 배치 비용을 절감시킬 수 있다. 또한 고정 함수 엔진과 프로그래머블 엔진의 긴밀한 결합을 통하여 펌웨어 업데이트 만으로 앞으로 적용될 새로운 머신러닝 기능에 대한 지원이 가능하게 한다.
Arm 머신러닝 프로세서는 이러한 전력, 효율성 및 유연성의 결합을 통해 앞으로 다가 올 미래에서의 엣지용 머신러닝 추론을 재정의한다. 개발자들은 이를 통해 오늘날 최적의 사용자 경험을 창출하면서도 미래 응용 분야의 요구사항까지 만족할 수 있다.
글 / 이안 포사이스(Ian Forsyth) Arm 제품 마케팅 디렉터




