

[첨단 헬로티]
머신비전산업에서 인공지능 기술(머신러닝, 딥러닝)이 빠르게 확산되고 있다. 인공지능 기술을 통해 기존의 컴퓨터비전 기술로는 어려웠던 검사가 가능해질 뿐만 아니라 ‘데이터의 자기 학습’으로 보다 빠르고 쉬우며 신뢰성과 유연성을 갖춘 머신비전 검사가 가능해졌다. 이에따라 자연스럽게 인공지능 기술에 대한 관심이 높아지고 있다. 국내 대표적인 머신비전 전문업체인 라온피플은 ‘LAON PEOPLE’s 머신러닝 아카데미’를 통해 인공지능의 대표적인 기술인 머신러닝 기술에 대해 연재한다.
1. Overview

기계학습을 위한 알고리즘 - Neural Network
PART I에서는 총 4회의 걸쳐, 기계 학습의 기본 개념과 종류에 대해서 알아보았다.
우리가 늘 기대하는 것처럼, 아무런 지침을 주지 않더라도 데이터만 넘겨주면 알아서 해주는 꿈 같은 일은 좀 더 있어야 되겠지만, 기계학습 이론은 꾸준히 발전을 하고 있다.
여기서 잠깐만 시선을 돌려보자.
사람마다 편차가 있겠지만, 사람이 모국어를 배우는데 수년까지 걸리고, 글을 배우는데도 몇 달에서 수년까지 걸릴 수도 있고, 어떤 사람은 평생을 걸쳐도 학습이 되지 못하는 경우도 있다. 제2 외국어에 대해서는 말할 필요도 없다.
기계학습의 경우도 사람이 배우는 시간만큼 학습을 시켜준다면 상당한 결과가 있을 것으로 예상되지만, 그렇게 오랜 기간 학습을 시키는 것을 별로 좋아하지 않는 것 같다.
기계학습에는 많은 알고리즘(이론)이 발표가 되었으며, 대표적인 것 중 하나가 신경망(Neural Network)이다. 정확히 말하면 인공신경망(ANN, Artificial Neural Network)이지만, 줄여서 신경망(NN)이라고 많이 부른다.
Neural Network - 생물학적 신경망의 구조
사람이 학습하는 방식을 비슷하게 구현한 것이 인공신경망이며, 이는 상당한 역사를 갖고 있다.
인공신경망의 구조를 알아보기에 앞서 ‘생물학적 신경망’을 먼저 살펴보면 다음 그림 1과 같다.
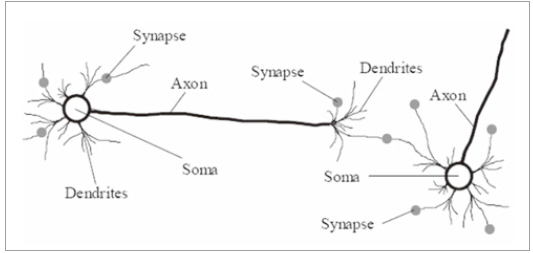
▲ 그림 1
신경 세포(뉴런)의 구성은 크게 다음 4가지로 구성이 된다.
ㆍ수상돌기 (Dendrite): 외부로부터의 신경 자극을 받아들이는 역할을 한다.
ㆍ축삭돌기 (Axon): 가늘고 길게 뻗어 있는 섬유 모양을 하고 있으며, 전류와 비슷한 형태로 다른 뉴런으로 신호를 전달하는 기능을 담당한다.
ㆍ신경세포체 (Soma): 신경 세포의 핵을 담당하는 부분으로 여러 뉴런으로부터 전달되는 외부 자극에 대한 판정을 하여 다른 뉴런으로 신호를 전달할 것인지를 최종 결정을 한다.
ㆍ시냅스 (Synapse): 어떤 뉴런의 축삭돌기 말단과 다음 뉴런의 수상돌기의 연결 부위를 말한다. 이 시냅스는 얇은 막의 형태이며, 다른 뉴런의 축삭돌기로부터 받는 신호를 어느 정도의 세기(strength, weight)로 전달할 것인지를 결정한다.
Neural Network - 인공 신경망의 구조
학습을 하게 되면, 한 신경 세포에서 다른 신경 세포로 연결되는 시냅스 부분에서 신호의 세기가 결정이 되고 굳어지게 된다. 즉, 특정 자극에 학습의 기대치대로 결과를 낼 수 있도록 각각의 시냅스의 세기가 결정이 된다.
위 그림 4에서 볼 수 있는 것처럼, 인공 신경망은 생물학적 뉴런의 구조를 모방하여 만들어졌다.
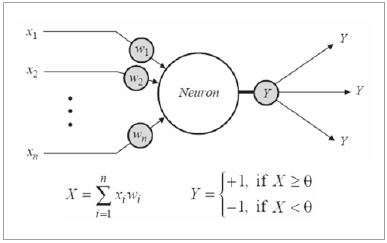
▲ 그림 4
수상돌기에 해당되는 입력에(x1, x2, …, xn) 시냅스에 해당하는 입력의 가중치(w1, w2, …, wn)를 곱하고 이것들의 총합이 신경세포체(Soma) 부분으로 전달이 되면, 신경 세포체에서는 활성함수(activation function)에 따라 최종 출력 Y가 결정이 된다. 위 그림에서는 활성 함수가 특정 경계값(threshold)과 비교를 하여 같거나 크면 ‘+1’을 출력하고 작으면 ‘-1’을 출력한다.
인공신경망(ANN)은 보통 이런 뉴런들을 multi-layer로 구성을 하며, 뒤에서 설명하게 될 역전파(back-propagation) 알고리즘을 통해 신경망의 학습 결과가 기대치와 비슷한 결과를 낼 수 있도록 뉴런의 입력으로 들어오는 시냅스의 가중치를 계속 조절해가는 과정을 거친다.
이것을 훈련(training)이라고 하며, 훈련 데이터를 통한 반복 훈련을 통해 가중치(w1, w2, …, wn)의 최적값이 정해지게 된다.
현재 인공신경망은 문자 인식, 필기체 인식, 음성 인식 등의 분야에서 놀라운 성과를 보이고 있으며, 경제학적 모델을 해석하는데도, 석유의 연간 소비량을 예측하는데도, 영상이나 동영상의 자동 태깅 분야에서도 좋은 결과를 내고 있다.
2. History
Neural Network(신경망) 역사

Neural Network의 역사는 다른 과학의 분야와 마찬가지로 오랜 개발 기간이 소요되었으며, 그 동안 여러 번의 부침이 있었다. 신경망의 역사는 1940년대 초반으로 거슬러 올라갈 수 있으며, 컴퓨터 개발의 역사와 거의 비슷하다고 볼 수 있다.
그래서 초반의 인물들을 살펴보면, 많은 사람들이 컴퓨터의 개발자들과 겹치는 것을 볼 수 있다 신경망의 역사를 구분하는 방식은 사람마다 견해가 다르지만, 여기서는 4개의 시기로 나누는 방식을 따른다.
ㆍ태동기
ㆍ황금기
ㆍ긴 침묵기
ㆍ르네상스기
(1) 태동기
1943년, McCulloch와 Pitts는 산술연산과 논리연산을 수행할 수 있는 간단한 신경 망에 기초한 연산 모델(computational model)을 만들고 이것을 발표하였으며, 이 논문은 이후의 Neural Network에 많은 영향을 끼치게 된다.
1949년 심리학자인 Hebb은 “The Organization of Behavior”라는 책을 발표했으며, 뉴런의 시냅스에 기반한 학습의 법칙(learning law)을 발표하였고, 심리학적인 실험 결과를 이 학습의 법칙에 의해 설명하였다.
후에 이것은 Hebbs의 이름을 따 ‘Hebbian learning’이라고 불린다.
(2) 황금기
1950년대와 60년대는 신경망의 황금기로 불린다. 1951년 Minsky는 Snark라는 이름을 갖는 neurocomputer를 개발했으며, 가중치(weight)을 자동으로 조절할 수가 있었다. 하지만 실제로 구현이 되지는 못했다.
1957년 Rosenblatt는 신경망에서 흔히 사용되는 “perceptron”이라는 용어 및 알고리즘을 개발했고, 후에 Rosenblatt는 perceptron에 기반한 최초의 성공적인 Neuro-Computer를 개발했으며, 이것을 패턴 인식 분야에 적용하였다.이 perceptron이 많은 일을 할 수 있을 것으로 전망이 되었지만, 얼마 안돼 제한이 많이 있음이 밝혀졌다.
Single layer perceptron는 선형적으로 분리가 가능한 패턴은 인식할 수 있지만, 복잡한 패턴은 2개 혹은 그 이상의 layer를 갖는 신경망(multi-layer) 신경망에서 가능하다는 것이 1969년 Minsky에 의해 증명이 된다. 오늘날 perceptron은 한 쪽 혹은 다른 쪽에 속하는 것을 결정할 수 있는 binary classifier에 대한 지도 학습 알고리즘의 개념으로 사용이 되고 있다.
또한 Minsky는 perceptron으로는 XOR을 학습할 수 없다는 XOR problem을 밝히고 결국 이것은 신경망에 대한 관심이 멀어지게 만드는 계기가 되었다.
(3) 긴 침묵기
1970년대에 들어서면서 연구비에 대한 지원이 줄고, 학회도 거의 없어지면서 논문이 출간되는 횟수도 크게 줄어들게 된다. 하지만, 개별적으로 신경망에 대한 연구는 지속이 되었으며, 독자적으로 신경망에 대한 패러다임을 발전시켰다. 그리고 이 시기의 연구들은 80년대 후반 르네상스 시대의 밑거름이 된다.
1976년 Grossberg는 많은 논문을 발표했으며, 그의 연구는 후에 Carpenter에 의해 ART(Adaptive resonance theory)로 발전을 하게 된다.
1982년 Kohonen은 Kohonen map이라고도 알려진 SOM(self-organization feature map)을 발표했다. 또한 Hopfield는 Hopfield 망을 발표하였다. 후에 SOM과 ART를 통하여 신경망을 자율학습(unsupervised learning) 분야에 적용을 할 수 있게 된다.
(4) 르네상스기
1982년과 1984년에 저명한 물리학자 Hopfield는 널리 읽히는 신경망 관련 논문 2편을 발표하였으며, 전세계를 돌면서 강의를 통해 신경망에 대한 연구를 활성화 시키기를 촉구한다. 이는 많은 연구자들이 다시 신경망에 관심을 갖게 되는 계기가 되었다.
1986년, Rumelhart와 Hinton이 드디어 그 유명한 back-propagation 알고리즘을 발표하면서 신경망은 많은 문제들을 풀 수 있게 되었다. 1987년에는 최초로 신경망에 대한 국제 conference가 열리게 되고, 그 다음 해에는 신경망에 대한 국제 journal이 만들어지게 되었다.
1995년 LeCun과 Bengio는 CNN(Convolutional Neural Network)를 발표한다. CNN을 이용하여 local invariant feature를 쉽게 추출이 가능하고, 기존 신경망이 갖는 문제점을 극복할 수 있게 되었으며, 문자 인식이나 음성 인식 분야에서 탁월한 성능을 얻을 수 있게 되었다.
하지만 신경망이 갖는 복잡도나 적절한 hyper-parameter 설정이 없이는 좋은 결과를 기대할 수도 없고, 좋은 hyper-parameter 설정을 경험적인 방법에 많이 의지해야 하는 어려움이 있었다.
이로 인해 기계학습 분야에서 SVM(Support Vector Machine)이나 이것보다 훨씬 간단한 linear classifier 같은 알고리즘에 신경망이 점차 뒤로 밀리는 분위기가 되었다,
하지만, 2000년대 후반부터 부각된 딥러닝(deep learning) 때문에 다시 한번 신경망 연구에 불이 붙게 된다. 2006년 이전에는 hidden layer가 2개 이상이 되는 심층망을 학습 시킬 뾰족한 방법이 별로 없어 고생을 하였다. 몇 개의 CNN을 제외하면 거의 학습을 성공시키지 못했다고 보는 편이 맞을 것 같다. 그러다가 2006년이 되면서 약간의 시차를 두고 신경망의 거장이라고 할 수 있는 Hinton, Bengio, LeCun 교수의 연구팀들이 심층망을 학습시킬 수 있는 AutoEncoder 방식을 찾아내고 비로소 딥러닝의 기반이 마련되었다.
2012년에 발표된 AlexNet은 혁신적인 성능으로 세상을 놀라게 하고, 또한 소스코드를 공개함으로써 많은 연구자들이 딥러닝의 세계로 들어갈 수 있는 기반이 되었으며, 이후 연구자들은 더욱 성능을 발전시키면서 소스 코드를 공개하는 전통을 이어가면서 불과 5년만에 세상이 깜짝 놀랄만한 발전이 있었다.
3. Basic Theory
Hebbian Rule

앞서, 신경망의 역사([Part II. Neural Networks] 2. History )에서 살펴보았던 것처럼, 1949년 심리학자인 Donald Hebb은 뉴런의 시냅스에 기반한 학습의 법칙을 발표하였다. 그는 생물학적인 신경망에서 학습이 이루어지면 특정 입력으로 들어오는 신호 자극에 잘 반응할 수 있도록 시냅스들의 세기가 결정이 된다는 사실에 주목했다.
그의 이름을 딴 Hebbian rule에 따르면, 학습이란 시냅스 연결의 세기(strength)를 조정하는 것으로 정의했으며, 기본적인 학습 방법은 2개의 뉴런이 동시에 활성화 시키려면, 뉴런이 연결된 가중치(weight)를 높이면 된다.
Perceptron의 개념
1957년에 Rosenbalt는 “Perceptron”이라는 용어 및 개념을 발표했다. 발표 당시, 뉴런의 활성함수(activation function)로 “step function”을 사용했기 때문에 지금처럼 “sigmoid function”을 사용하는 뉴런에 비해 제약이 많았지만, 입력의 중요도에 따라 출력이 결정이 되는 수학적 모델로서는 의미가 있다.
여기서 입력의 중요도는 가중치에 따라 결정된다는 개념이 도입이 되었으며, 그림3처럼, 2 layer feed forward 구조에서는 여러 개의 입력을 받아 1개의 출력을 결정하는 신경망의 경우를 살펴보면, 출력은 가중치와 입력의 곱의 합이 특정 기준(threshold) 보다 작으면 0이 되고, 크면 1을 출력한다.
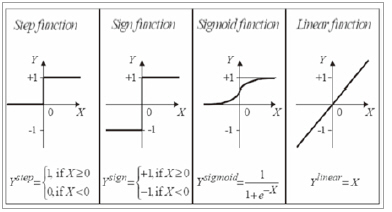
▲ 그림 3
Perceptron의 한계
Rosenbalt의 Perceptron은 그 개념상 생물학적인 신경망의 특성을 잘 반영한 것 같지만, 한계가 있다. Perceptron의 문제는 뉴런의 활성화 함수가 step function이기 때문에, 출력이 0과 1처럼 극단적인 결과만을 도출할 수 있다. 2 layer 만으로 구성이 되거나, 아주 단순한 결과를 도출해야 하는 경우는 문제가 없지만, 뉴런의 출력이 0과 1로 극단적인 상황만 있기 때문에 다중 layer 신경망의 경우는 좋은 결과를 얻기가 어렵다.
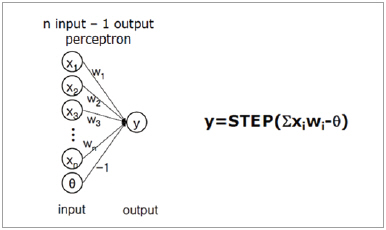
▲ 그림 4
최적의 학습 결과를 갖는 신경망을 설계하려면, 나중에 자세히 다루겠지만, 역전파(back-propagation)와 gradient-descent 방법을 사용한다. 이 개념은 근본적으로 입력이나 특정 넷의 가중치를 약간 변경시키면, 출력에 작은 변화가 일어난다는 점에 근거하고 있다.
Perceptron 기반의 뉴런은 weight나 bias의 작은 변화가 출력 쪽에 작은 변화를 만들어내면서 섬세하게 신경망을 학습을 시킨다는 오늘날의 학습 개념과는 부합이 잘 안된다.
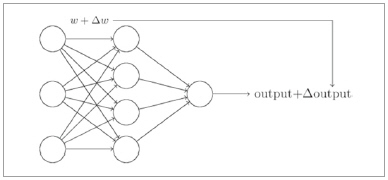
▲ 그림 5
Sigmoid Functions
해결책은 활성함수로 Perceptron처럼 Step function을 사용하는 대신에, “Sigmoid 함수”를 사용하는 것이다. 활성화 함수로 “Sigmoid 함수”를 사용하면, 0에서 1까지 연속적으로 변하는 출력값을 갖기 때문에, 가중치나 바이어스를 조금 변화시켰을 때 출력이 조금씩 변화하도록 만들 수 있다. Sigmoid 함수는 아래와 같은 식을 갖는다.
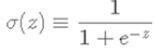
여기서 z는 각각의 입력(x1, x2, x3, …)과 가중치(w1, w2, w3, ..)를 곱한 값에 bias를 더한 값이며, 입력이 결정이 되면, 가중치나 바이어스를 약간 변화시켰을 때(즉 편미분을 하였을 때), 출력이 그에 상응하여 변화하는 것을 확인할 수 있다.
Gradient-Descent
여기서 중요한 점은 가중치나 바이어스의 작은 변화량에 대해서 출력의 변화량이 linear 하다는 점이다. 이런 선형적인 특성으로 인해, 가중치나 바이어스를 조금씩 바꾸면서 출력이 원하는 방향으로 움직이도록 만들 수 있다.
이것을 유식한 용어로는 Gradient-Descent 방법이라고 하며, 최적값을 찾아갈 때 흔히 사용하는 방법이다.
좀 더 부연설명을 하면, gradient-descent 방법은 오목한 그릇에서 공을 굴리는 경우를 생각하면 이해하기가 쉽다. 어떤 지점에서 굴리기를 시작할지라도, 그릇의 밑바닥까지 내려가면 최적값에 도달했다고 볼 수가 있다.
이 때 내려가는 방향을 선택하려면, 공이 특정 위치에 있을 때, 그 미분값(gradient)가 음이 되는 방향을 선택하면 된다.
이 과정을 반복하다 보면 공은 결국은 바닥에 내려가게 되듯이, 어떤 특정 위치에서 시작을 하더라도 그 위치에서 편미분의 값이 음수가 되는 방향을 계속 선택하면 최적값에 도달하게 된다.
Supervised Learning
이것은 어떻게 보면 학습의 원리와 유사하다. 미리 값을 알고 있는 훈련 데이타를 통해, 가중치와 바이어스를 조금씩 변화시켜 가면서 출력이 최적의 상태가 되도록 하는 방법이 바로 지도 학습(supervised learning)이다.
가중치와 바이어스의 최적값을 찾아가는 방법은 얼핏 보면 쉬워 보이지만, 1개의 뉴런에 여러 개의 입력이 연결이 되고, 또 그런 뉴런이 여러 개가 있다면 변화시켜야 할 가중치와 바이어스가 점점 많아지게 된다.
어떻게 최적값을 찾아갈 수 있을까? 막연하게 막고 품는 방식으로 여러 개의 값들을 무작위로 바꿔 간다면 과연 최적값에 도달할 수 있을까?
이것에 대한 해답은 역전파(back-propagation) 방법을 사용하면 된다.
4. Backpropagation (역전파)
Backpropagation의 알고리즘의 기원
신경망에서 가장 중요한 개념 중 하나가 바로 역전파(backpropagation)이다. 이 “역전파”를 통해 “역방향으로 에러를 전파(backward propagation of error)” 시키면서 최적의 학습 결과를 찾아가는 것이 가능해졌다.
참고로, 역전파 알고리즘은 1970년대 개발이 되었지만 (그 이전에 개발이 되었다고 주장하는 사람들도 있지만, 대략적으로 70년대로 봄), 1986년 Rumelhart와 Hinton의 논문을 통해 최적의 신경망 변수들을 찾아내는데 적합함이 증명이 되었고, 비로소 빛을 보게 되었으며, 신경망에 대한 연구에 다시 불을 붙이는 촉매제가 되었다.
Backpropagation 이해를 위한 사전 지식
① Cost Function (Loss Function)
역전파에 대한 본격적인 설명에 앞서, “cost function” 혹은 “loss function”의 개념을 먼저 파악을 해야 할 필요가 있다. cost function은 아래와 같이 정의된다.
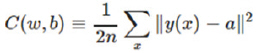
여기에서 n은 훈련에 사용하는 입력의 수를 나타내고, y(x)는 입력 x를 가했을 때의 기대(target) 출력을 나타내며, a는 입력 x를 신경망에 넣었을 때의 실제 출력이다.
이 식으로부터 짐작할 수 있겠지만, cost function이란 신경망에 훈련 데이터 x를 가하고 실제 출력과 기대 출력간의 차에 대한 MSE(Mean Square Error)를 구하는 것임을 알 수가 있다.
y(x)와 a의 차가 작아질수록 신경망이 학습이 잘된다고 볼 수 있으며, 훈련 데이터를 이용해 가중치(w)와 바이어스(b)를 변화시키는 과정을 반복적으로 수행하여 cost function이 최소값이 되도록 하는 것이 신경망 학습의 목표이다.
② Gradient-descent 방법에 기반한 학습
위 식처럼, cost function이 정의가 된다면, 과연 어떻게 w와 b값들을 변화시켜야 최적의 결과를 얻을 수 있을까?
신경망의 뉴런의 개수가 많아지고, 입력의 수가 많아질수록 더욱 더 해를 구하기가 어려워진다. 이 때 필요한 개념이 gradient-descent 방법이다.
Gradient-descent에 대한 설명 중 위키에 나온 설명이 재미있게 잘 된 것 같다. 위키피디아의 설명에 따르면, ‘안개가 끼어있는 산정상에서 한치 앞이 보이지 않는다면, 어떻게 내려가야 할까?
짙은 안개로 인해 앞이 잘 보이지 않는다면, 자기의 현재 위치에서의 정보 (local information)만을 활용해야 하며, 그 정보로는 가장 경사가 큰 쪽으로 내려가는 길을 택하면 된다.’
어느 정도 위치에 바닥이 있는지는 정확하게 알 수은 없지만, 항상 현재 위치에서 기울기가 가장 큰 방향으로 내려간다면 결국 바닥에 도달할 수 있게 된다. 물론 local minimum에 빠질 수도 있겠지만, 단지 국소 정보만을 활용할 때는 가장 많이 사용하는 것이 gradient-descent이고, 최대값을 찾는 경우에는 gradient-ascent를 사용하면 된다.
마찬가지로, 훈련 데이터를 입력으로 가하고, cost function이 최소가 되도록 w와 b값들을 반복적으로 변화시켜가다 보면 결국, 최소값에 이를 수 있게 된다.
위 그림 6은 gradient-descent를 설명할 때 흔히 사용되는 그림으로, 어느 위치에서 시작을 할지라도 gradient가 음의 최대값 쪽으로 움직이게 되면, 결국 최소값이 도달할 수 있다.
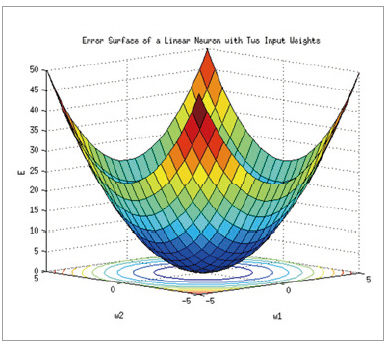
▲ 그림 6
단, 단점은 경사가 큰 경우는 빠른 속도로 수렴을 하지만, 거의 바닥에 오게 되면, 기울기가 작아지기 때문에 수렴 속도가 현저히 느려진다는 점이다.
역전파(backpropagation) 기본 개념
가중치(w)와 바이어스(b)값들을 조절하여 cost function이 최소가 되도록 하는 gradient-descent 개념을 이해 했다면, 어떻게 이 값들을 조절해야 할까?라는 의문이 생긴다. 신경망의 크기가 커지고, 입력이나 출력의 개수가 많아지면, 변수들이 너무 많기 때문에 이 작업은 매우 곤혹스러운 작업이 된다.
앞서 [Part II. Neural Networks] 3. Basic Theory 에서 “가중치나 바이어스 값을 아주 작게 변화를 시키면, 즉 편미분을 시키면, 출력 쪽에서 생기는 변화 역시 매우 작은 변화가 생기며, 작은 구간만을 보았을 때는 선형적인 관계가 있다”라고 했음을 상기하자.
이 말을 곰곰이 생각을 해보면, 작은 변화의 관점에서는 선형적인 관계이기 때문에, 출력에서 생긴 오차를 반대로 입력 쪽으로 전파시키면서 w와 b등을 갱신하면 된다는 뜻이 된다.
w와 b 값들을 무작위로 변화시키는 것이 아니라, cost function이 결국 w와 b의 함수로 이루어졌기 때문에, 출력 부분부터 시작해서 입력 쪽으로, 즉 역 방향으로, 순차적으로 cost function에 대한 편미분을 구하고, 얻은 편미분 값을 이용해 w와 b의 값을 갱신시킨다.
모든 훈련 데이터에 대해서 이 작업을 반복적으로 수행을 하다 보면, 훈련 데이터에 최적화된 w와 b 값들을 얻을 수 있다. 역전파(backpropagation)란 용어는 출력부터 반대 방향으로 순차적으로 편미분을 수행해가면서 w와 b값들을 갱신시켜간다는 뜻에서 만들어진 것이다.
뉴런의 재구성
역전파를 쉽게 이해하기 위해서 보통 뉴런의 구조를 아래 그림과 같이 재 구성을 할 수가 있다. 즉, 각각의 넷으로부터 들어오는 입력을 합하는 부분과 활성화 함수 부분을 나누어 생각하면, 역전파를 위해 편미분을 할 때 좀 더 쉽게 이해를 할 수가 있다. 아래 그림 7에서 f(e)는 sigmoid 함수에 해당이 되며, e는 각 넷으로부터 입력과 가중치의 곱의 총합을 나타낸다.
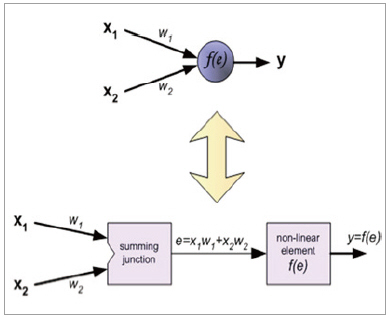
▲ 그림 7
역전파의 기본 스텝
역전파는 보통 2단계를 거친다. 먼저 feed forward과정을 거치면서 입력이 최종 출력까지 전달되고 최종 출력단에서 에러와 cost function을 구한다. 다음은 backpropagation 단계이며, 최종단에서 구한 기대 출력과 실제 출력간의 차(에러)를 반대 방향으로 전파시키면서 각각 넷이나 뉴런의 가중치(w)와 바이어스(b) 값을 갱신한다.
이 과정을 좀 더 이해를 쉽게 하기 위해, 뉴런을 재구성하면 그림 8과 같다.
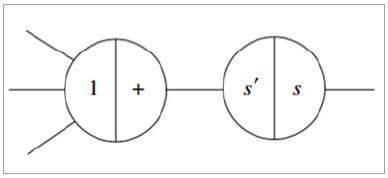
▲ 그림 8
위 그림 8에서 s는 활성 함수, 즉 sigmoid 함수를 뜻하며, s’는 s의 미분 함수이다. Feed forward 과정에서는 왼쪽에서 오른쪽으로 흐름이 만들어지며, 위 그림의 원에서 오른쪽 반원에 있는 부분에 해당된다.
즉, 모든 넷에서 들어오는 입력의 합을 sigmoid 함수를 거쳐서 출력을 함을 의미한다. Backpropagation을 하는 경우는 오른쪽에서 왼쪽으로 계산을 하며, 연산을 수행할 때는 왼쪽 반원에 있는 부분을 선택한다.
즉, 에러를 역전파할 때는 sigmoid 함수의 미분 함수 s’를 사용하고 각 net로 모두 동일하게 전파가 된다.
역전파의 과정 종합
앞서 설명한 것처럼, 역전파는 feed forward와 backpropagation의 2단계로 구성이 된다. Feed forward 단계에서는 훈련데이타를 신경망에 인가하고 출력단에서의 에러와 cost function 을 구한다. 신경망이 충분히 학습이 되지 못한 경우는 오차가 클 것이며, 이 큰 오차값을 backpropagation 시키면서 가중치와 바이어스 값을 갱신한다.
훈련 데이터에 대해서 반복적으로 이 과정을 거치게 되면, 가중치와 바이어스는 훈련데이타에 최적화 된 값으로 바뀌게 된다. 좋은 학습 결과를 얻으려면, 이 훈련 데이터가 한쪽으로 치우치지 않고 범용성을 가져야 한다는 것은 따로 설명하지 않아도 이해가 될 것 같다.
아래 그림은 feed forward 과정을 거쳐서 이미 에러(δ)를 구하고, 역전파를 통해 반대 방향으로 에러를 전파시키는 과정을 보여주기 위한 것이다.
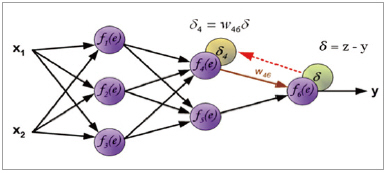
▲ 그림 9
위 그림 9에서처럼, 에러(δ)를 구하고, 얻어진 에러를 이용해 (δ4)를 구하여, 비슷한 방식으로 (δ5)를 구할 수 있다. 이렇게 얻어진 정보를 이용해 아래 그림10처럼 (δ1)을 구할 수 있다.
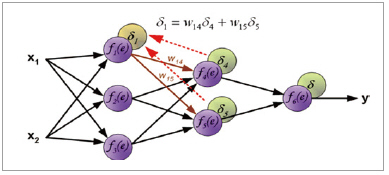
▲ 그림 10
이렇게 반복적으로 에러를 전파시키면서 가중치와 바이어스 값을 갱신한다.
Sigmoid 함수의 좋은 성질과 delta rule
이전에 설명을 했듯이 Sigmoid 함수는 좋은 성질을 갖고 있다. 앞서 살펴본 장점 이외에도 미분을 하게 되면 매우 편리한 성질이 있음을 할 수 있다.
f(x) = Sigmoid(x)로 정의를 하게 되면, f의 미분, 즉, 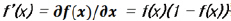 를 얻을 수 있다. 이 관계식을 이용하면, back-propagation 식을 좀 더 쉽게 풀어낼 수 있다.
를 얻을 수 있다. 이 관계식을 이용하면, back-propagation 식을 좀 더 쉽게 풀어낼 수 있다.
Sigmoid 함수를 미분하면 위와 같은 식을 갖기 때문에 역전파에 사용하는 δ는 δ = (target-out) out(1-out)과 같이 쉽게 계산을 할 수가 있다. 이것을 delta rule 이라고 부른다.
Learning rate (학습 속도 조절 변수)
가중치나 바이어스 값을 갱신할 때는 편미분을 통해서 얻어진 값을 곧바로 곱하지 않고, 학습속도를 조절하기 위한 변수 (이것을 learning rate)를 곱해준다. 보통 η를 사용하며, 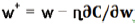 처럼 사용한다.
처럼 사용한다.
Backpropagation은 처음 접했을 때, 기본 개념은 어느 정도 이해가 가더라도 아마 알쏭달쏭한 부분이 있을 것이다.
다음에서는 간단한 신경망 회로에서 backpropagation이 어떻게 적용이 되는지 실제 예를 들어 설명할 예정이다. Case Study를 살펴보면 더 이해가 깊어질 것이라 확신한다.
[역전파 요약]
1. Neural Network - Backpropagation은?
ㆍ최적의 학습 결과를 찾기 위해 역방향으로 에러를 전파(backward propagation of error)
2. Backpropagation 이해를 위한 Cost function 개념
ㆍ입력된 훈련 데이터에 관한 실제 출력과 기대 출력간의 차이
ㆍcost function이 최소값이 되도록(실제 출력과 기대 출력의 차이가 없도록) Backpropagation
3. Backpropagation 이해를 위한 Gradient-descent 개념
ㆍcost function이 최소가 되도록 하는 방법
ㆍcost function의 인자인 가중치(w)와 바이어스(b)를 조절함
4. Backpropagation의 두 단계
ㆍfeed forward: 입력 -> 출력(최종 출력단에서 에러와 cost function을 구함)
ㆍbackpropagation: 출력부터 반대 방향으로 순차적으로 편미분을 수행해가면서
ㆍ뉴런의 가중치(w)와 바이어스(b) 값을 갱신
5. Backpropagation에서 Sigmoid 함수를 사용하는 이유
ㆍBackpropagation을 해석하기에 편리한 Sigmoid 함수의 미분 성질
Case Study - Backpropagation(역전파)

Backpropagation Case Study 목적
이제까지 Backpropagation(역전파)의 원리 및 개념에 대해서 알아보았다. 역전파에 대해서 기본 개념은 이해를 했을지라도 실제 이것이 어떻게 적용이 되는지 완전하게 이해를 못했을 수도 있다. 뒤에서는 역전파의 주요 개념인 “feed forward”와 “error backpropagation”이 실제 어떻게 적용이 되는지에 대해 설명할 예정이다.
구체적인 예를 들어 설명하는 것이 좋겠지만, 이미 설명이 잘 된 자료를 활용하는 것도 좋은 방법 중 하나이다.
다음에서는 설명이 잘 된 2개의 자료를 소개할 예정이다. 이 2개의 자료는 backpropagation에 대한 수식의 전개나 유도 등 수학적인 부분에 치중하는 대신에 개념을 이해시키는 것을 목적으로 그림을 통해 단계별 과정을 보여주거나, 실제 숫자를 대입하여 backpropagation의 2 단계가 어떻게 적용이 되는지를 보여준다.
Case Study 1.
먼저 소개할 자료는 아래 그림11처럼 간단한 신경망 회로에 대해서 backpropagation이 진행되는 과정을 단계별로 그림으로 나타내고, 거기에 친절한 주석을 단 자료이며, 그 사이트에 대한 링크는 다음과 같다.
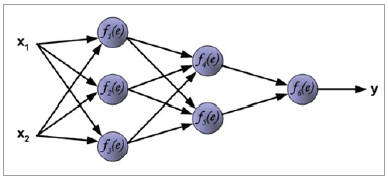
▲ 그림 11
http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
입력 x1과 x2가 출력 y로 나오기까지 각각의 넷에 있는 가중치를 이용해서 중간 hidden neuron의 값을 풀어내고, 그 값들을 이용해 최종 y 값을 결정한다.
이렇게 결정된 y는 원래의 target 값과 비교하여 오차(error)를 구하고, 그렇게 구한 오차값을 역방향으로 전파를 시키면서, 오차가 최소화되도록 가중치 값들을 갱신한다. 이 자료는 어려운 수식을 사용하지 않고도 그림만으로 흐름을 설명하는 훌륭한 보조 자료인 것 같다.
Case Study 2.
위 자료까지 보더라도 잘 이해가 가지 않는다면, “Matt Mazur”의 블로그 자료가 튜토리얼이나 실 예제 관점에서 가장 설명이 잘된 것 같다. 아래는 그의 블로그에 대한 링크이다.
http://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
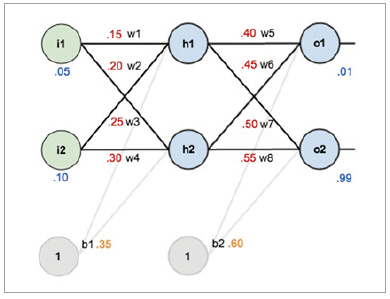
▲ 그림 12
위 그림 12는 Matt Mazur의 글에서 실제 예를 들 때 사용한 간단한 신경망 회로이다. 빨간색은 가중치나 바이어스의 초기값을 나타내며, 파란색은 training data(훈련 데이터)이다.
즉, 입력으로 i1에 0.05를 넣고, i2에는 0.10을 넣은 후에 o1과 o2에서 각각 0.01과 0.99를 나오는지 실제 계산을 해본다. 이 예제에서는 뉴론의 활성화 함수로 sigmoid 함수를 사용했으며, 앞서 그림을 이용한 자료에서도 보았듯이 순차적으로 계산을 한다.
실제 계산을 수행했더니 o1은 약 0.75가 나왔고 o2는 약 0.77이 나왔기 때문에 상당한 오차가 발생했음을 알 수 있다. 이 오차를 다시 반대 방향으로 전파를 시키면서 w1~w6의 값을 갱신한다. 이 때 학습의 속도를 고려하는 학습 진도율(η)이 등장하며, 이 예제에서는 0.5를 사용하였다.
친절하게도 source code까지 공개를 하였으니, 이 값을 바꿔보면 학습의 속도가 달라짐을 확인할 수 있을 것이다. 이 방식으로 w1~w6의 값을 모두 갱신을 하였다면, 다시 훈련 데이터를 i1과 i2에 넣고 위 과정을 반복한다. 반복하다 보면, o1과 o2가 원래의 학습 목표였던 0.01과 0.99에 근사한 값이 도달 될 수 있을 것이다.
이 때의 w1~w6 는 훈련 데이터를 통해 최적화 된, 즉 학습이 된, 상태가 되는 것이다. 이 예제는 총 10000회를 반복적으로 수행하면, 원하는 값에 도달하게 된다.
훈련 데이터가 많아지고 신경망에 있는 뉴런의 숫자가 많아질수록 학습 시간이 길어지고, 초기값이나 학습 진도율 변수가 학습에 상당한 영향을 끼칠 것이라는 것에 대한 감을 잡게 될 것으로 확신한다.
위 2개의 링크에 있는 자료는 Google 검색을 통해, 필자가 찾은 예 중에서 가장 잘된 자료 같다. 역전파에 대한 이해에 도움이 되길 기대한다.
(주)라온피플








































